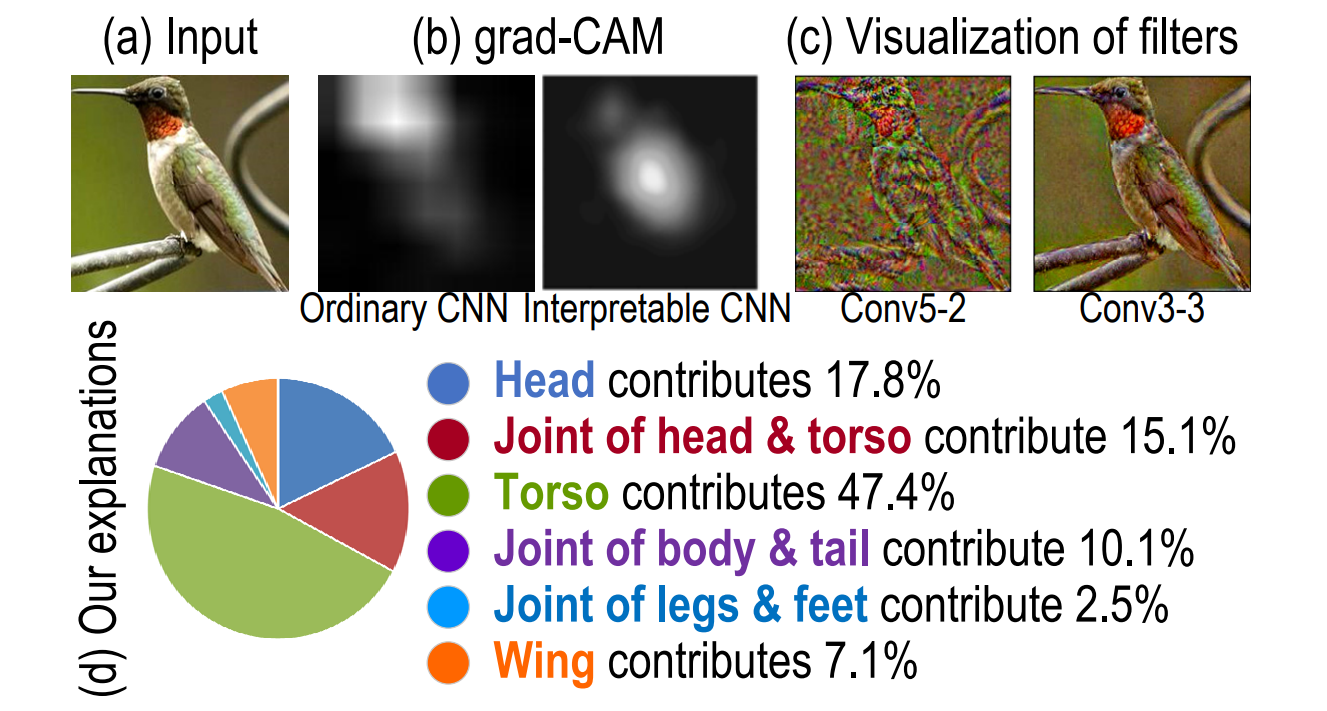
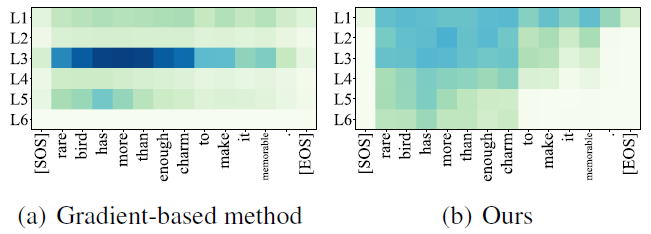
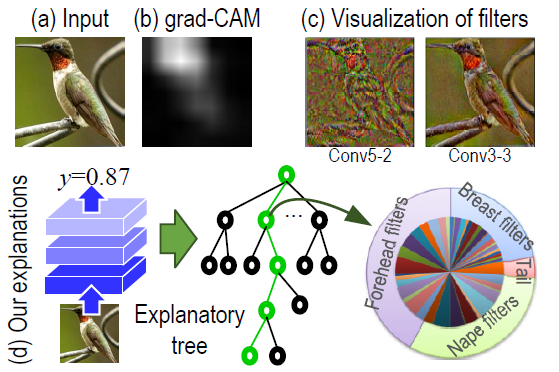
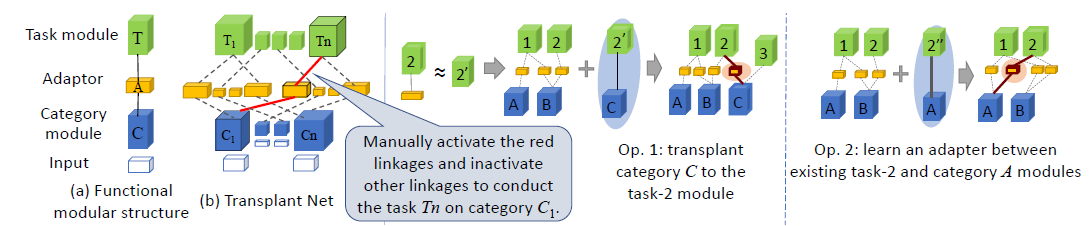
Currently, I am an associate professor at Shanghai Jiaotong University, leading
the Lab for Interpretability and Theory-Driven Deep
Learning.
Before that, I received the B.S. degree in machine intelligence at Peking University, China, in
2009. I obtained the M.Eng. degree and the
Ph.D. degree at University of
Tokyo, in 2011 and 2014, respectively, under
the supervision of Prof. Ryosuke Shibasaki. In 2014, I became a postdoctoral
associate at the University of California,
Los Angeles, under the
supervision of Prof. Song-Chun
Zhu.
Due to the black-box nature of DNNs, interpretable machine learning has become a
compelling topic. However, the trustworthiness and applicability of interpretable ML has
been widely questioned in recent years. Core critisms include the following five aspects.
Current explanation methods are built upon different heuristics, lacking common theoretical
foundations.
It is infeasible to objectively evaluate the correctness of the explanation results, in the
absence of ground truth explanations.
There is still a large gap between the semantic explanation result (e.g., the attribution-based
explanation) and the explanation of a DNN’s performance (e.g., the generalization power), which
cannot be unified.
Traditional semantic explanations cannot be used as feedbacks to guide the designing of DNNs,
thereby boosting DNN performances.
Most current methods boosting DNN performances are heuristic, and the theoretical mechanisms
behind their success are largely missing.
Therefore, our team aims to solve two key scientific problems:
how to develop a theoretical system to unify different explanations of the semantics encoded in
a DNN (e.g., attribution-based explanations, taxonomy of semantic concepts, and etc) and unify
different explanations of the DNN performance (e.g., the generalization power, adversarial
robustness, adversarial
transferability, and etc). Besides, it is highly desirable to bridge the two types of
explanations. We believe that, an explanation system can be considered as trustworthy if the
methods in the system can be mutually verified.
how to extract the common mechanism behind different heuristic methods, which
include both explanation methods and current popular methods boosting the DNN performance.
Research Map
Publications
Defects of Convolutional Decoder Networks in Frequency Representation
Ling Tang, Wen Shen, Zhanpeng Zhou, Yuefeng
Chen, and Quanshi Zhang
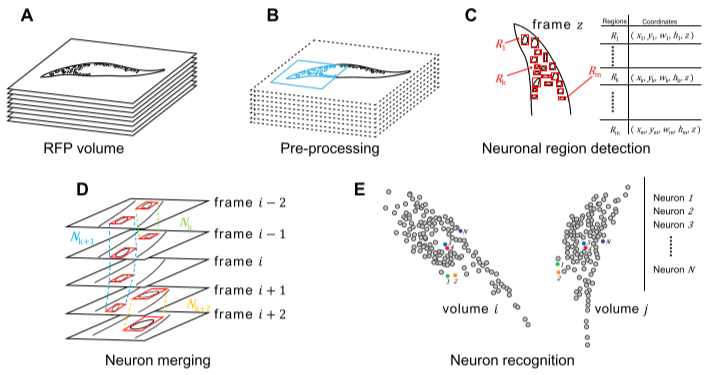
Rapid Detection and Recognition of Whole Brain Activity in a Freely Behaving
Caenorhabditis Elegans
Yuxiang Wu, Shang Wu, Xin Wang, Chengtian
Lang, Quanshi Zhang, Quan Wen, and Tianqi Xu
A Unified Game-Theoretic Interpretation of Adversarial Robustness
Jie Ren*,
Die Zhang*,
Yisen Wang*, Lu Chen,
Zhanpeng Zhou,
Yiting Chen, Xu Cheng,
Xin Wang, Meng Zhou, Jie Shi
and Quanshi Zhang
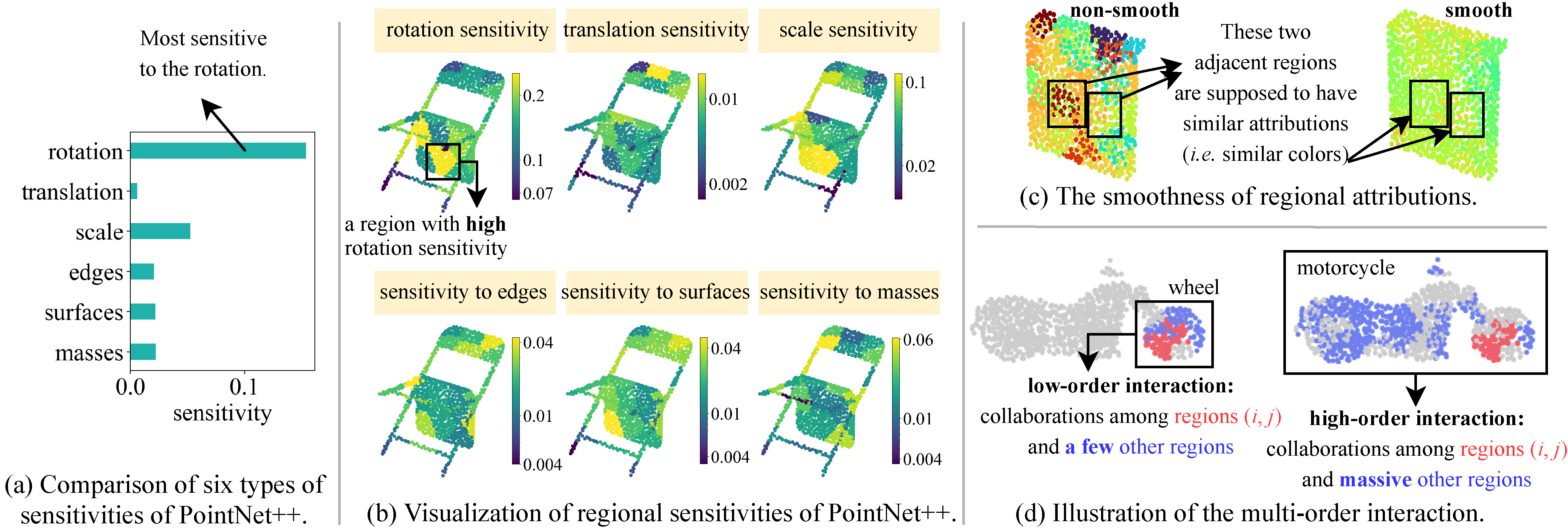
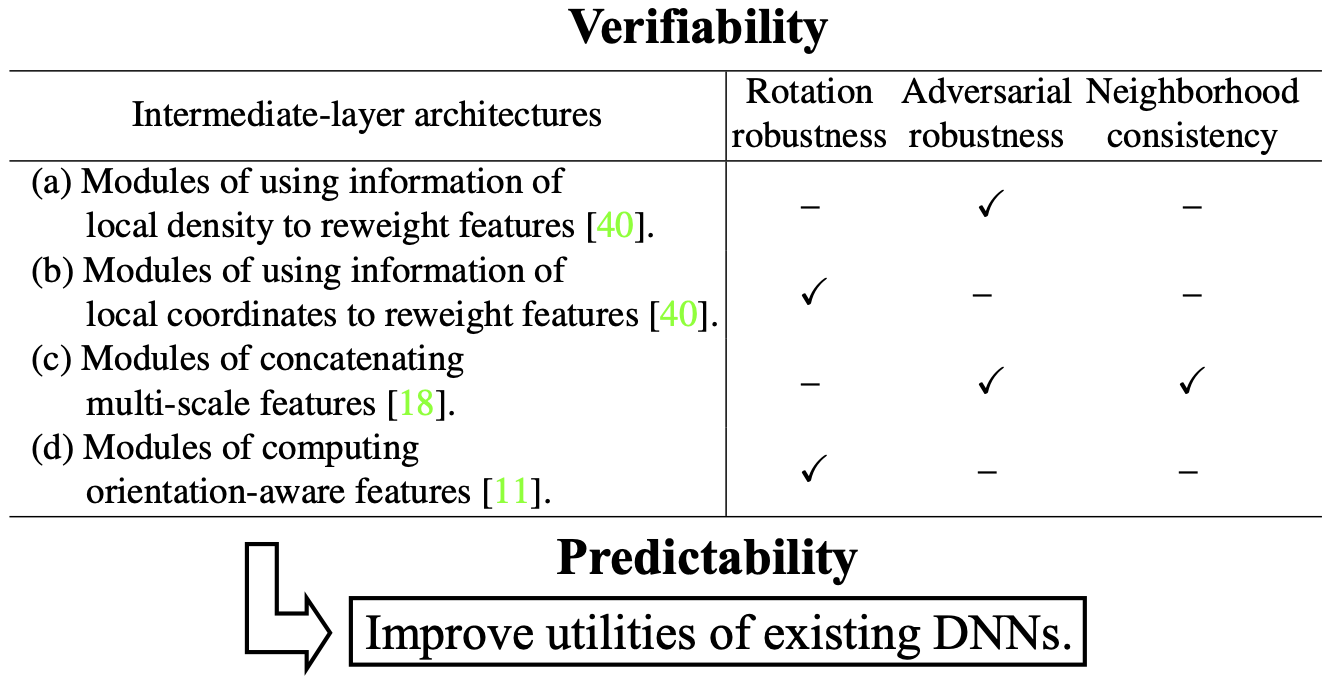
Verifiability and Predictability: Interpreting Utilities of Network
Architectures for 3D Point Cloud Processing
Wen Shen*, Zhihua Wei*, Shikun Huang, Binbin
Zhang, Panyue Chen, Ping Zhao,
and Quanshi Zhang
A Unified Approach to Interpreting and Boosting Adversarial Transferability
Xin Wang*,
Jie Ren*,
Shuyun Lin, Xiangming Zhu,
Yisen Wang, and Quanshi
Zhang
Building Interpretable Interaction Trees for Deep NLP Models Die Zhang*, Huilin Zhou, Hao Zhang, Xiaoyi Bao, Da
Huo, Ruizhao Chen, Xu
Cheng, Mengyue Wu, Quanshi Zhang
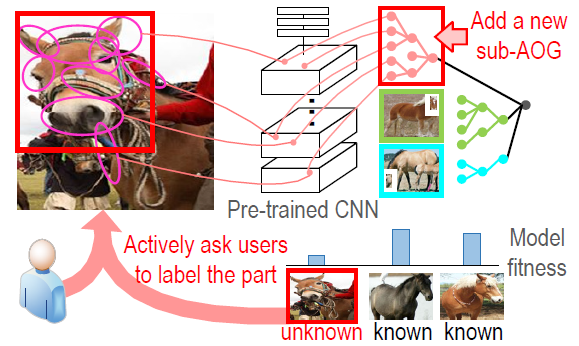
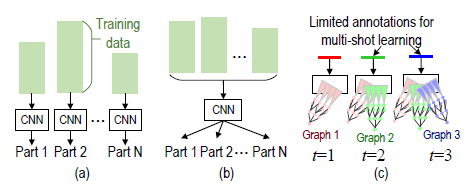
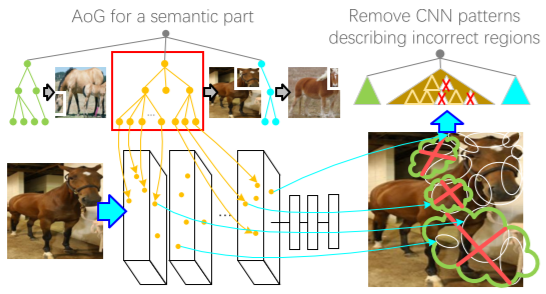
Mining Interpretable AOG Representations from Convolutional Networks via Active
Question Answering
Quanshi Zhang,
Jie Ren, Ge Huang, Ruiming Cao, Ying Nian Wu,
and Song-Chun Zhu
Visual Graph Mining for Graph Matching
[Paper] Quanshi Zhang, Xuan Song, Yu Yang, Haotian Ma, Ryosuke Shibasaki
Computer Vision and Image Understanding, vol. 178, page 16-29, 2019
Mining Deep And-Or Object Structures via Cost-Sensitive Question-Answer-Based
Active
Annotations [Paper] Quanshi Zhang, Ying Nian Wu, Hao Zhang, and Song-Chun Zhu
Computer Vision and Image Understanding, vol. 176-177, page 33-44, 2018
Object Discovery: Soft Attributed Graph Mining
[Paper][Project
Website][Code] Quanshi Zhang, Xuan Song, Xiaowei Shao, Huijing Zhao, and Ryosuke
Shibasaki
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
38(3):532-545,
2016
From RGB-D Images to RGB Images: Single Labeling for Mining Visual
Models [Paper] Quanshi Zhang,
Xuan Song, Xiaowei Shao, Ryosuke Shibasaki, Huijing Zhao
ACM Transactions on Intelligent Systems and Technology (ACM-TIST), 6(2): 16, 2015
Attributed Graph Mining and Matching: An Attempt to Define and Extract Soft
Attributed Patterns [Paper][Project Website][Video Spotlight][Video][Code] Quanshi Zhang, Xuan Song, Xiaowei Shao, Huijing Zhao, and Ryosuke Shibasaki
CVPR 2014
Learning Graph Matching: Oriented to Category Modeling from Cluttered
Scenes [Paper] Quanshi Zhang, Xuan Song, Xiaowei Shao, Huijing Zhao, and Ryosuke
Shibasaki
ICCV 2013
Category Modeling from just a Single Labeling: Use Depth Information to Guide the
Learning of 2D Models [Paper][Video] Quanshi Zhang, Xuan Song, Xiaowei Shao, Huijing Zhao, and Ryosuke
Shibasaki
CVPR 2013
Other Directions
Rapid Detection and Recognition of Whole Brain Activity in a Freely Behaving
Caenorhabditis Elegans
[Paper]
Yuxiang Wu, Shang Wu, Xin Wang, Chengtian Lang, Quanshi Zhang, Quan Wen, and
Tianqi Xu
PLOS Computational Biology, 2022
Prediction and Simulation of Human Mobility Following Natural Disasters
[Paper]
Xuan Song, Quanshi Zhang, Yoshihide Sekimoto, Ryosuke Shibasaki, Nicholas
Jing
Yuan, and Xing Xie
ACM Transactions on Intelligent Systems and Technology (ACM-TIST), 8(2): 29, 2016
Unsupervised Skeleton Extraction and Motion Capture from 3D Deformable
Matching [Paper][Video] Quanshi Zhang, Xuan Song, Xiaowei Shao, Ryosuke Shibasaki, and Huijing
Zhao
Neurocomputing, Elsevier, pp.170-182, 2013
Intelligent System for Human Behavior Analysis and Reasoning Following
Large‐scale
Disasters [Paper]
Xuan Song, Quanshi Zhang, Yoshihide Sekimoto, Teerayut Horanont, Satoshi
Ueyama,
and Ryosuke
Shibasaki
IEEE Intelligent Systems, vol. 28, no. 4, pp. 35-42, July-Aug. 2013
A Fully Online and Unsupervised System for Large and High Density Area
Surveillance:
Tracking, Semantic Scene Learning and Abnormality Detection [Paper]
Xuan Song, Xiaowei Shao, Quanshi Zhang, Ryosuke Shibasaki, Huijing Zhao,
Jinshi
Cui, and Hongbin Zha>
ACM Transactions on Intelligent Systems and Technology (ACM‐TIST), 4(2): 20, 2013
A Novel Dynamic Model for Multiple Pedestrians Tracking in Extremely Crowded
Scenarios [Paper]
Xuan Song, Xiaowei Shao, Quanshi Zhang, Ryosuke Shibasaki, Huijing Zhao, and
Hongbin Zha
Information Fusion, Elsevier, 2012
RASAT: Integrating Relational Structures into Pretrained Seq2Seq Model for
Text-to-SQL
Jiexing Qi, Jingyao Tang, Ziwei He, Xiangpeng Wan, Yu Cheng, Chenghu Zhou, Xinbing Wang,
Quanshi Zhang, and Zhouhan Lin
EMNLP 2022
A Simulator of Human Emergency Mobility following Disasters: Knowledge Transfer from
Big Disaster Data
[Paper]
Xuan Song, Quanshi Zhang, Xuan Song, Yoshihide Sekimoto, Ryosuke Shibasaki,
Nicholas Jing Yuan, and Xing Xie
AAAI 2015
When 3D Reconstruction Meets Ubiquitous RGB-D Images
[Paper][Video][Video Spotlight] Quanshi Zhang, Xuan Song, Xiaowei Shao, Huijing Zhao, and Ryosuke Shibasaki
CVPR 2014
Start from Minimum Labeling: Learning of 3D Object Models and Point Labeling
from a
Large
and Complex Environment [Paper][Video] Quanshi Zhang, Xuan Song, Xiaowei Shao, Huijing Zhao, and Ryosuke Shibasaki
ICRA 2014
Prediction of Human Emergency Behavior and their Mobility following Large-scale
Disaster [Paper]
Xuan Song, Quanshi Zhang, Yoshihide Sekimoto, and Ryosuke Shibasaki
KDD 2014
Intelligent System for Urban Emergency Management During Large-scale
Disaster [Paper]
Xuan Song,Quanshi Zhang, Yoshihide Sekimoto, and Ryosuke Shibasaki
AAAI 2014
Unsupervised 3D Category Discovery and Point Labeling from a Large Urban
Environment [Paper][Video][Slides] Quanshi Zhang, Xuan Song, Xiaowei Shao, Huijing Zhao, and Ryosuke
Shibasaki
ICRA 2013
Modeling and Probabilistic Reasoning of Population Evacuation During Large-scale
Disaster [Paper]
Xuan Song, Quanshi Zhang, Yoshihide Sekimoto, Teerayut Horanont, Satoshi
Ueyama,
and Ryosuke Shibasaki
KDD 2013
Laser-based Intelligent Surveillance and Abnormality Detection in Extremely
Crowded
Scenarios [Paper]
Xuan Song, Xiaowei Shao, Quanshi Zhang, Ryosuke Shibasaki, Huijing Zhao, and
Hongbin Zha
ICRA 2012
Moving Object Classification using Horizontal Laser Scan Data
[Paper]
Huijing Zhao, Quanshi Zhang, Masaki Chiba, Ryosuke Shibasaki, Jinshi Cui, and
Hongbin Zha
ICRA 2009
Research Post
Interaction Interpretability of Neural Networks
Chapter 1 Introduction
In 2018, I started to post on the online platform "Zhihu" (similar
to
Quora) for my research about
the interpretability of DNNs. At that point my paper was finally accepted for the first time after being
repeatedly discouraged by the trend of pursuing higher prediction scores on a certain task. Only then
can I
say it out loud “beyond visualization, there is another path to interpretability.” Two years later, I
still
insist on posting, because I want everyone to know if all explanation methods are only self-justified,
but
cannot be verified by each other, then neither of them can be considered as a fully correct method.
There
are only a few solid studies in Explainable AI, such as the Shapley value, which satisfies four
mathematical
axioms for a "correct attribution heatmap", including linearity, nullity, symmetry, and efficiency.
Explanations that satisfy the above four axioms can be considered as rigorous explanations. If there is
no
theory to ensure the rigor and objectivity of explanation methods, then sooner or later the
interpretation
research will disappear.
(Note that this is not an article to discourage you from doing research on Explainable AI. I am
semi-confident in the future of explainable AI —— there is a chance that nothing you will achieve, that
you
will end up with publishing some papers, or that you will actually do some solid work. This is sometimes
the
most exciting and promising research. Therefore, I still keep going.)
The "objective rigor" of interpretability often means "generality" and "uniqueness", i.e., "the
explanation
of the only standard. "Generality" is easy to understand, which means that the algorithm should be more
standard and have more connections to previous theories, rather than being a scenario-specific ad-hoc
technique. In contrast, the "uniqueness" has been rarely mentioned, some people even ask "why should the
explanation be unique?" Here we need to impose some restrictions on "what is a good explanation?" E.g.,
what
conditions must be satisfied by a good explanation, and then "uniqueness" is embodied in the unique
solution
under these conditions. To a smaller extent, conditions for explanations can be the four axioms
corresponding to the Shapley value; to a larger extent, conditions for explanations can also be the
scope of
application of the interpretability metrics. For example, the same metric can "explain semantics,
generalization, and transferability".
Let's jump out of the topic that we just discussed and now let's face the whole picture of explainable
AI.
Whether a research direction is "alive" or "sustainable in the future" does not lie in the number of
papers
published in the field, nor in the number of citations, but in the number of essential problems in the
research direction that have not been addressed mathematically. (Here we refer to the solid modeling,
rather
than deliberately hooking up a new concept). After all, I still remember the saying by Professor
Song-Chun
Zhu "deep learning has died" in 2006, a sentence enough for me to digest for many years - when a person
blocks all the shortcuts for publishing papers, you need to plan a road from the mud, which may be the
right
way to go - although it is likely to die on the halfway, we have to be prepared.
Now, let's go back to talk about the explainable AI. The original purpose of explainable AI is very
simple,
that is, to provide theoretical guidance for the training and design of neural networks, and to test the
reliability of the information modeled by neural networks. In brief, a reliable explainable AI study
needs
to satisfy requirements simultaneously:
Direct theoretical modeling of the target to be explained is required, rather than proposing
indirect
algorithms intuitively.
Quantitative explanatory results are needed, instead of qualitative ones.
The objectivity (or rigor) of the explanatory results needs to be evaluated, rather than just
requiring
that the explanatory results look good.
For many emerging problems in explainable AI, sometimes we cannot provide a direct evaluation or the
ground-truth of neural networks. Thus, we need a more solid theoretical system to prove the rigor of
mathematical modeling.
For example, the rigor of Shapley value is guaranteed by the four axioms it satisfies.
Similarly, an explanation method needs to satisfy a large number of axioms or exhibits good
properties to demonstrate the rigor of the explanation method.
Besides, if different explanation methods or metrics can be mutually validated, then such
explanations are often more rigorous.
Explanation theories need to be extended to explaining various phenomena in real-world applications,
or
to provide direct guidance on the design and training of neural networks.
Chapter 2
Chapter 3
Chapter 4
Chapter 5
Chapter 6
Chapter 7 From Practice to Theory: Adversarial Transferability of Neural
Networks
Introduction
Hello, we are Xin Wang and Jie Ren, students of Dr. Quanshi Zhang. In this article, we would like to
share some new insights to adversarial transferability of DNNs.
—— Note that this paper is not based on empirical experiments, instead, we investigated the nature of
adversarial transferability of DNN (though not very rigorously), while the experiments serve as an
aid to verification. Please pay attention to this.
Although deep learning has been rapidly developed in the last decades, they have encountered
bottlenecks. On the one hand, many algorithms are proposed based on trial and error from empirical
experiments, which lack solid and reliable theoretical foundations; on the other hand, these studies
usually based on simple assumptions, which are detached from the actual problems and cannot guide the
design and optimization of DNNs.
Therefore, we believe the new trend for deep learning is to build a complete theoretical system and use
it to guide applications. If an algorithm only stays at the experimental level without theoretical
explanation, then such an algorithm just like “Shennong”, a divine farmer in ancient China, who tasted
hundreds of herbs to test their medical value. People cannot explain why such an algorithm works, then
the significance of the algorithm might be limited to make a small improvement on performance, which
constrains further explorations. In contrast, if we can prove and grasp the common effective components
shared by many different algorithms, just like deriving the common effective ingredients from hundreds
of herbs, then the algorithm can be considered effective and reliable. Thus, these insights can be used
to guide the design of network structure and improve the performance of DNNs.
In this article, we take the adversarial transferability of DNNs as an example to made attempts along
this direction. We have obtained some shallow conclusions to suggest possible explanations for the
previous algorithms that were proposed to improve the adversarial transferability. We hope to extract
some common effects in previous algorithms, and further improve the algorithm transferability. Although
we cannot ensure that these conclusions essentially reflect the nature of adversarial transferability,
we try to ensure that our results reflect some of the common effects of previous algorithms. Besides,
taking this study as a basis, we further explore the intrinsic nature of adversarial transferability.
Enhancing adversarial transferability: from practice to theory
In recent years, adversarial samples have attracted much attention in the field of deep learning. Behind
the superior performance of neural networks, there lies a very dangerous security risk —— adding a small
imperceptible perturbation to the input sample can completely change the prediction of a neural network.
Such maliciously modified input samples are called adversarial samples. Researchers also found that
these adversarial samples are transferable, which means that an adversarial sample generated on neural
network A may also be able to attack neural network B.
Many approaches have been proposed to enhance the adversarial transferability. However, the intrinsic
mechanism of these methods to enhance the transferability remains unclear, just like different herbs
tasted by Shennong. Although these methods can indeed enhance transferability, people are still unclear
about which components that really work. Here we summarize several common approaches to enhance
transferability.
Variance-Reduced Attack (VR Attack): During the attack, Gaussian noise is added to
the input image to smooth the gradient against the input image.
Momentum Iterative Attack (MI Attack): Integrate the gradient momentum in the
optimization of adversarial perturbations.
Skip Connection Method (SGM Attack): For the residual block structure of the
network, increase the gradient weight of the skip-connection branch in the backpropagation process.
Diversity Input Attack (DI Attack): During the attack, introduce random padding and
random resizing on the input image to increase the diversity.
Translation Invariant Attack (TI Attack): Convolve the image gradient during the
attack.
Our goal is to extract the common effects from the above methods.
Adversarial Transferability: Extraction of useful components
We aim to explain adversarial transferability from a new perspective, the game-theoretic interaction
inside the adversarial perturbation. This explanation further extracts the common effects of the
previous transferability-boosting approaches.
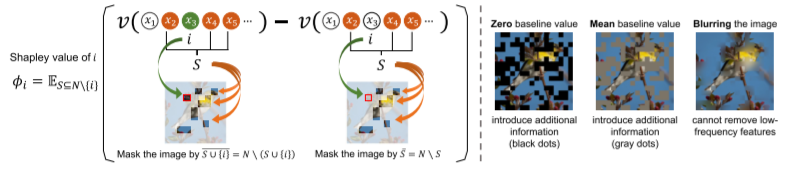
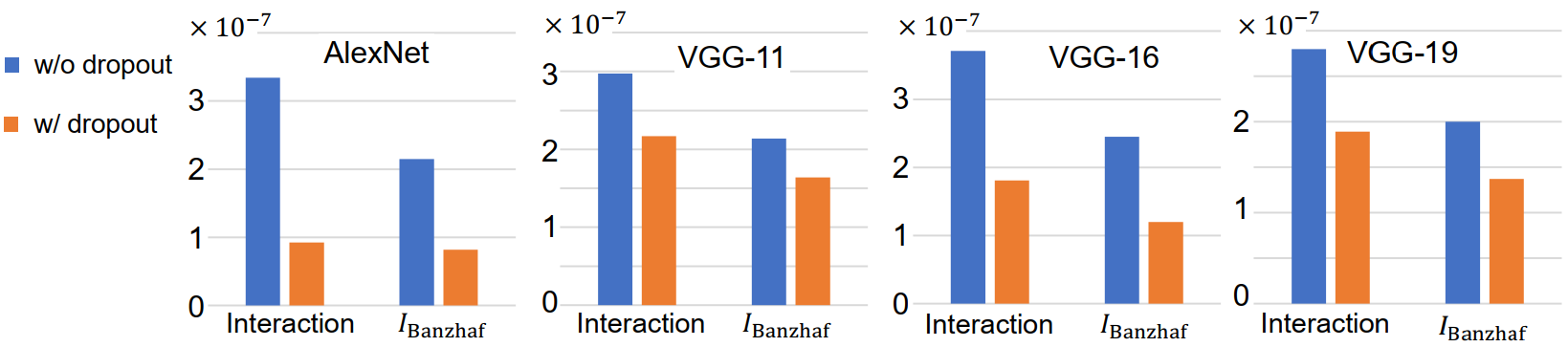
Basis: Game-theoretic interaction
We define the game-theoretic interaction between two units of the adversarial perturbation based on the
Shapley value in game theory. Shapley values measure the importance of different adversarial
perturbation units. For two adversarial perturbation units i and j, the game-theoretic interaction
between them embodies the influence of i and j on each other, which can be defined as: the importance of
i when j is always present minus the importance of i when j is not present. If the interaction is
greater than 0, it means that there is a positive interaction between i and j, which facilitates the
importance of each other. If the interaction is less than 0, it means that there is a negative
interaction between i and j, which decreases the importance of each other.
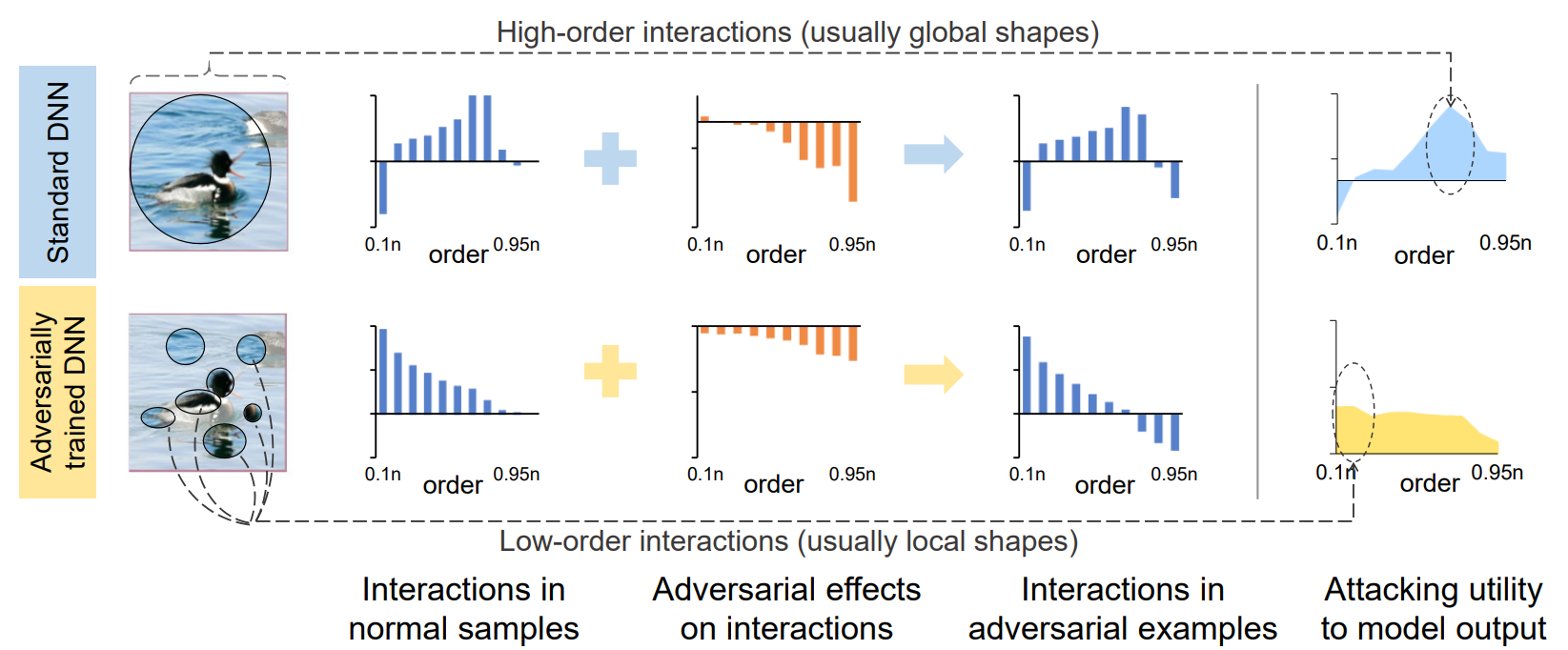
Motivation: multi-step attack vs. single-step attack
Previous studies have suggested that, compared with the single-step attacks, the adversarial
perturbations generated by multi-step attacks are more likely to overfit to the source neural network,
which result in lower transferability. We analyzed multi-step attacks and single-step attacks from the
perspective of game-theoretic interactions, and deduced that the adversarial perturbations obtained from
multi-step adversarial attacks usually exhibit larger game-theoretic interactions than those obtained
from single-step attacks.
Hypothesis: there is a negative correlation between adversarial transferability and
game-theoretic interaction
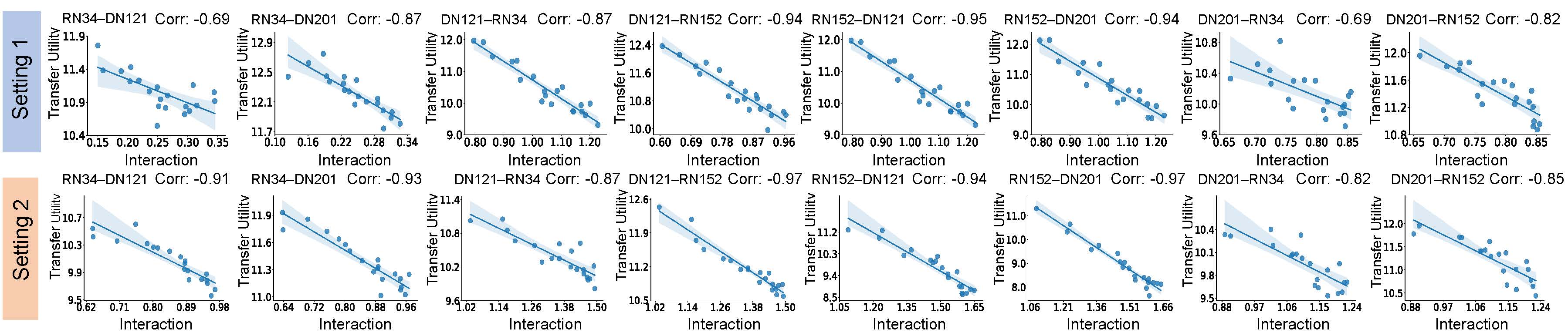
For single-step and multi-step attacks, we observed that:
Based on the above observations, we consider that the complex game-theoretic interactions reveal the
overfitting of the adversarial perturbations towards the source model, thus compromising its
transferability to the target network. Thus, we propose the following hypothesis.
The transferability of the adversarial perturbation is negatively correlated with the
interaction inside the perturbation.
Verification: Negative correlation between adversarial transferability and game-theoretic
interaction
We empirically compare the interactions of the less transferable adversarial perturbations with those of
the more transferable ones, and thus the negative correlation is verified. Based on the ImageNet
dataset, we generated adversarial perturbations on ResNet-34/152 (RN-34/152) and DenseNet-121/201
(DN-121/201), respectively, and transferred adversarial perturbations generated on each ResNet to
DenseNets. Similarly, we also transferred adversarial perturbations generated on each DenseNet to
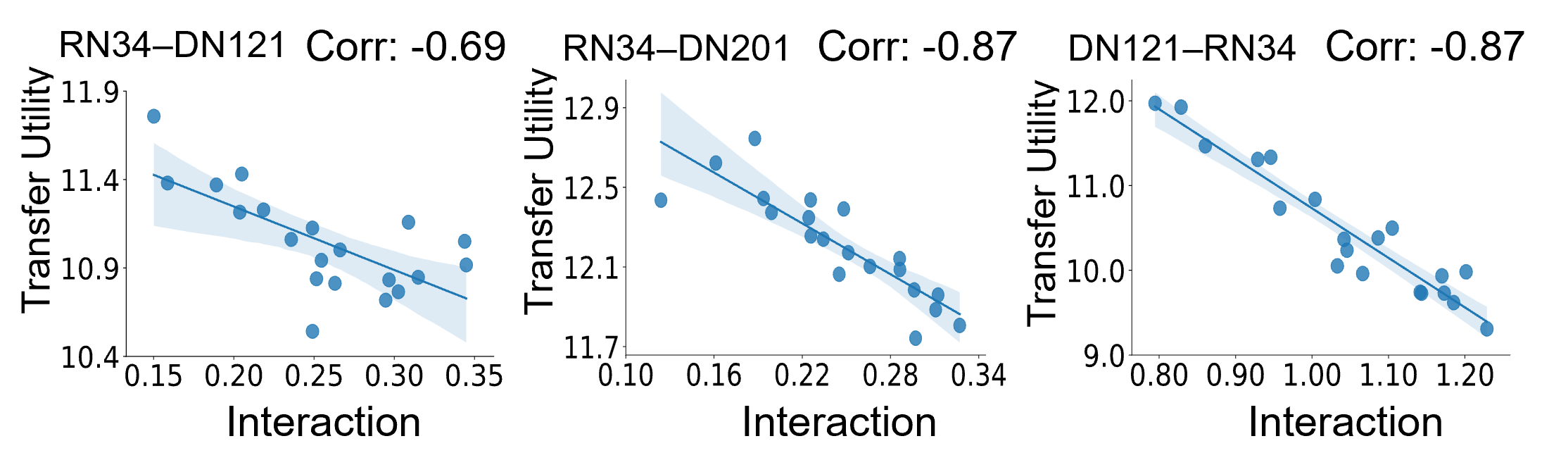
ResNets. Figure 1 shows the negative correlation between adversarial transferability and game-theoretic
interaction, where the horizontal axis indicates the average interaction of adversarial perturbations
through all testing images, and the vertical axis represents the average transfer utility of adversarial
perturbations on the target DNN.
Figure 1. The negative correlation between the transfer utility and the interaction. The
correlation is
computed as the Pearson correlation. The blue shade in each subfigure represents the 95%
confidence interval of the linear regression.
A unified explanation: Reducing game-theoretic interaction is the common effects of various
transferability-boosting methods
Beginning from the negative correlation between adversarial transferability and game-theoretic
interaction, we extracted the common effective component from various previous methods of enhancing
adversarial transferability, which is reducing game-theoretic interactions inside the adversarial
perturbation. We find that although the starting points and implementations of previous approaches to
enhance adversarial transferability are different, they all share the same effects - they all reduce the
game-theoretic interaction inside the adversarial perturbation during the attack. We theoretically
demonstrate that VR Attack, MI Attack, and SGM Attack produce adversarial perturbations with lower
interactions than the most common baseline (PGD Attack); we experimentally verify that DI Attack and TI
Attack reduce the interaction between perturbations.
Verification: Effectiveness of reducing game interactions
To further verify the negative correlation between the game-theoretic interaction and adversarial
transferability, we propose a loss function based on the game-theoretic interaction - directly
penalizing the interaction inside the perturbation in the attack. We optimize both the classification
loss function and the interaction-based loss function to generate the adversarial perturbation, which is
called the Interaction-Reduced Attack (IR Attack).
Experimental results show that the interaction-based loss function can significantly improve the
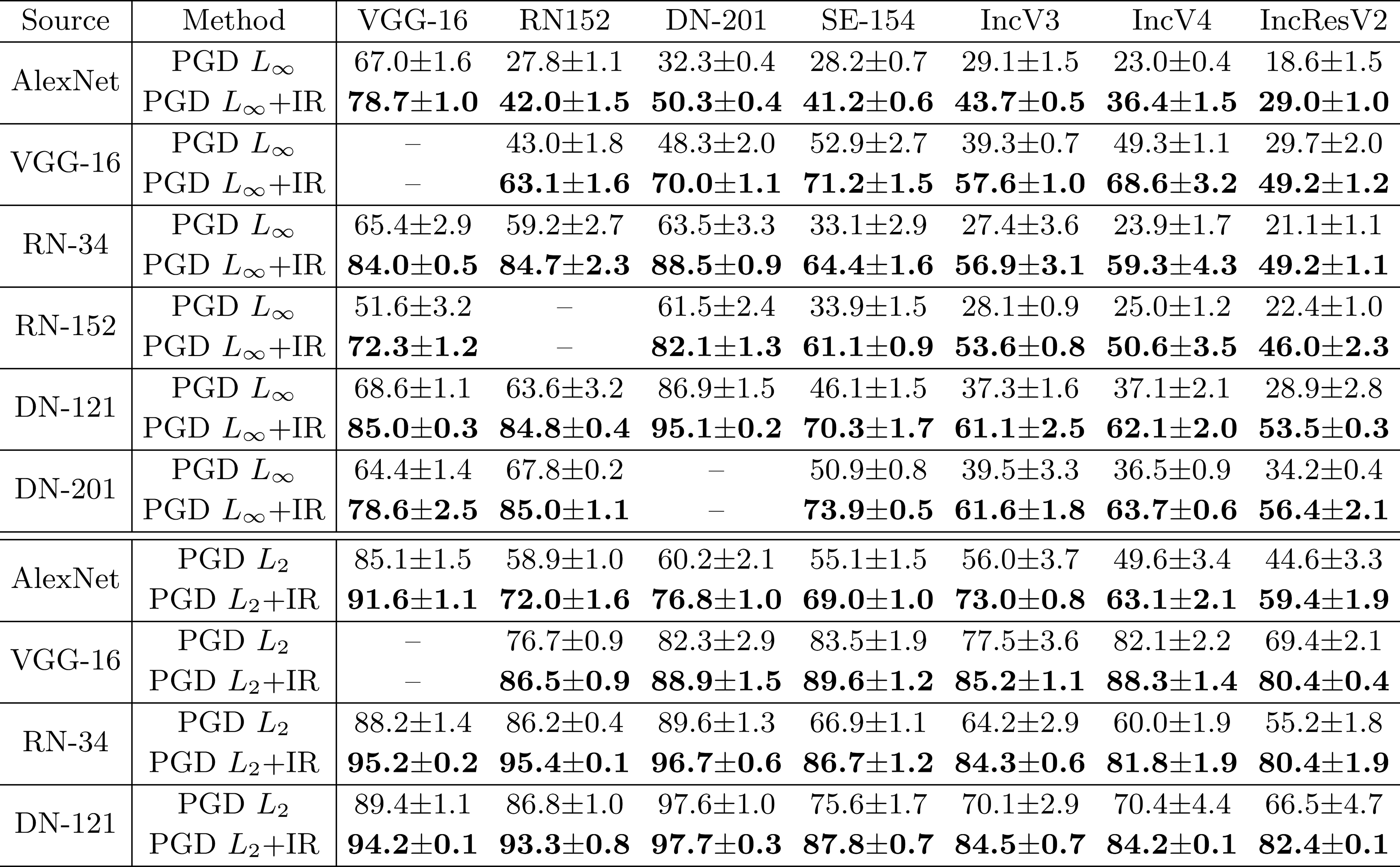
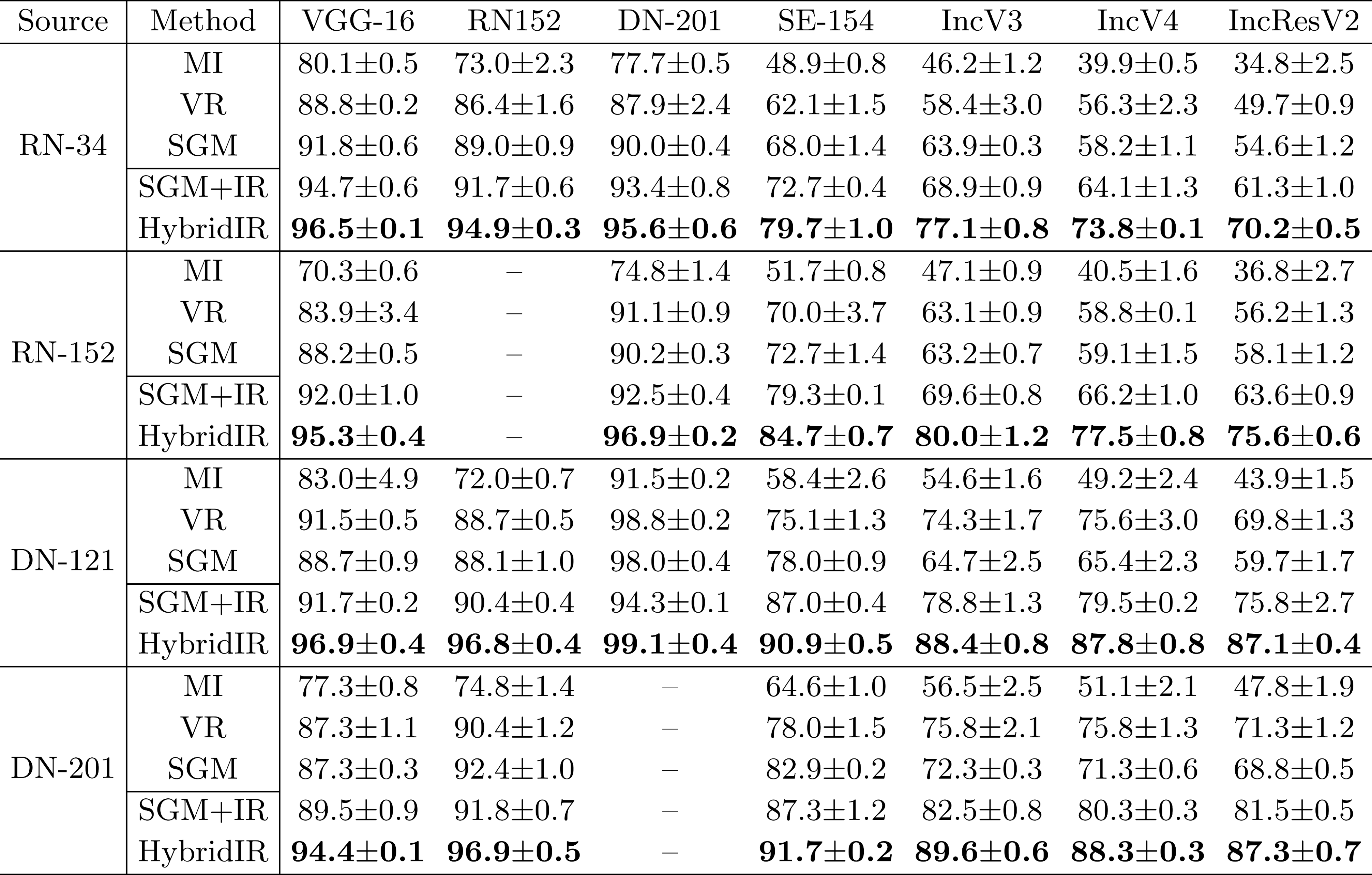
transferability of the adversarial perturbation. As shown in Table 1, compared with baseline methods,
the interaction loss function improves the transferability of adversarial examples by 8.2%~35.4%. It is
worth noting that the interaction loss is only a direct measure to reduce the game-theoretic
interaction, and we can combine it with previous attacks that reduce the interaction inside the
perturbation to jointly reduce the interaction inside the perturbations to further improve the
adversarial transferability. Therefore, we propose HybridIR Attack (MI+VR+SGM+IR Attack). In our
experiments, the HybridIR Attack increases the transferability of the adversarial examples from
54.6%~98.8% to 70.2%~99.1%.
Table 1: The success rates of \( L_1 \) and \( L_\infty \) black-box attacks crafted on six
source models,
including AlexNet, VGG16, RN-34/152, DN-121/201, against seven target models. Transferability of
adversarial perturbations can be enhanced by penalizing interactions.
Table 2: The success rates of \( L_\infty \) black-box attacks crafted on the ensemble model
(RN-34+RN-
152+DN-121) against nine target models.